IVS本へのツッコミ・第5章編
pp.141-142

- 人名用漢字の文字数として常用漢字までカウントしている。
- 戸籍法・戸籍法施行規則における常用漢字・人名用漢字の情報が古い(常用漢字改定以前)。常用漢字は「1,945字」ではなく「2,136字」。漢字の表(一)は「776字」ではなく「649字」。漢字の表(二)は「209字」ではなく「212字」。常用漢字と人名用漢字の合計(子の名に使える字)は「2,930字」ではなく「2,997字」。
- 「使われている漢字の種類」というタイトルの図だが、Adobe-Japan1-6の「23,058字」は漢字以外の字を多数含んでいる。
- 日本語漢字能力検定の情報が古い(常用漢字改定以前)。2級の範囲は常用漢字なので「約1,945字」ではなく「2,136字」。
- JIS第1水準から第4水準までの漢字数の合計は「10,038字」ではなく、「10,050字」。ちなみに「10,038字」は、この図に記載されているJIS第1水準から第4水準までの漢字数を足したもの(10,034字)とも一致しない。
- 第2水準は「3,388字」ではなく「3,390字」。3,388字はJIS X 0208:1983における第2水準の文字数。
- 第3水準は「1,245字」ではなく「1,259字」。JIS X 0213:2000では第3水準の文字数は1,249字だったが、これとも一致しない。
標準として規格化されている中でも最も多くの文字を規定しているのがJIS規格で、その文字数は約10,000です。一方で住民基本台帳のシステムで使用される住民基本台帳ネットワーク統一文字は19,432字、戸籍システムで使用される戸籍統一文字は55,267字、そして登記で使用される登記統一文字は65,597字と非常に膨大な文字を使用しています。情報交換用の工業規格(JIS)として規定されている文字数が第1水準から第4水準の合計10,038字であることを考慮すると、情報交換用の国内規格が住基や戸籍で使用されている5万を超える文字の全てを区別して扱うことができないのは明らかです。
- 「標準として規格化されている中でも最も多くの文字を規定しているのがJIS規格」というのは、おそらくJIS X 0213の漢字レパートリと常用漢字(人名用漢字も?)を比べているのではないかと思うが、①常用漢字や人名用漢字が「標準として規格化」されているとは言わないと思う。②国内限定の話なら、そう書いてほしい。③翻訳規格であるJIS X 0221を除外しているなら、そう書いてほしい。④「文字」とあるのが「漢字」のことならそう書いてほしい。
- 「住民基本台帳ネットワーク統一文字は19,432字」も漢字のみの数。また、これは2012年に入管漢字131字が追加される前の数で、現在は21,170文だと思う。
- 「戸籍統一文字は55,267字」も漢字のみの数。また、情報が古い。現在は55,271字だと思う。
- 「登記統一文字は65,597字」も漢字のみの数。登記統一文字については情報が少なく確かなことが言えないのだが、戸籍統一文字に登記固有文字を加えたものなので、戸籍統一文字の増加を反映しているはずであり、「65,597字」は最新の数字ではないと思う。
- しつこいようだが「第1水準から第4水準の合計」は「情報交換用の工業規格(JIS)として規定されている文字数」ではなく、漢字のみの数。また、「合計10,038字」ではなく「合計10,050字」。
p.143

p.144

- 一方のユーザがU+E000に、もう一方のユーザがU+E021に割り当てて、相互運用性に著しいダメージを与えているその字は、素のU+9089「邉」では?
p.145

- 図5-5で使われているフォントは小塚明朝だが、わざわざ作字してデフォルトグリフの「邉」をウソ字形にしている理由が不明。

p.146
具体的には、元となる文字と実際の表示・印刷で使用する字形を指定するセレクター(異体字セレクター/Ideographic Variation Selector)の二つのコードの組み合わせにより、意図している文字の字形を指定することができます(基底文字+異体字セレクター)。この二つの組み合わせで一つのグリフイメージを表現し、この二つのコードの組み合わせをIVS(Ideographic Variation Sequence)と呼びます。
p.147


- 異体字セレクタの「U+E010B」→「E0110」。
- U+9089とU+9089 U+E0110のグリフを両方とも小塚明朝で作字しているが、U+9089 U+E0110はHanyo-DenshiのIVSなのだから、Hanyo-Denshi用のフォントであるIPAmj明朝で表示するべきだと思う。制作環境がIVSに対応していなかったとしても、画像を貼るなり、方法はあるはず。
- U+9089の作字はIPAmj明朝のデフォルトグリフを再現できておらず(というか、何もせずに小塚のU+9089を使っていれば再現できていた)、Hanyo-DenshiのU+9089 U+E0119(JTBD47)と(「ハ」の2画目の反りの違いをどう見るかという問題はあるが)衝突している。
- U+9089 U+E0110の作字はHanyo-DenshiのJTBD69を再現できていない。
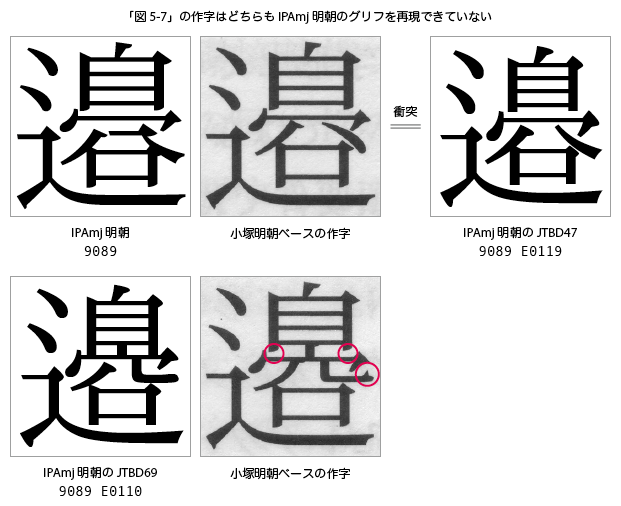
p.148

- U+9089のグリフに図5-7と同じ小塚明朝ベースで作字したものを使っているが、わざわざデフォルトグリフの「邉」をウソ字形にしている理由が不明。
- この図では小塚明朝(と小塚明朝ベースで作字したもの)が使われているが、Hanyo-Denshiフォントを用いるべきだと思う。
- 特にこの図の例文はひらがなも含んでいるため、読者にとってフォントが小塚明朝であることは明らかであり、小塚明朝がHanyo-DenshiのIVS(「9089 E0117」や「5091 E0104」)に対応しているように見えてしまう。
- 「9089 E0117」のグリフが、図5-7における「9089 E0110」と同じものになっているが、これは完全な間違い。

p.149
たとえば、図5-11の「龍」(U+7C60)の例では、そもそも登録されている文字の部分集合の数が異なります。Adobe-Japan1として登録されている文字一つ、しかしHanyo-Denshiとして登録されている文字は五つあります。このことは、Hanyo-Denshiより細かい違いを以て異なる文字として分別していることになります。

p.151
Adobe-Japan1は、アドビシステムズが独自に定めた主に字形集合です。この字形集合は、日本国内の標準規格であるJISC 6226-1978、JIS X 0208:1990、JIS X 0212:1990、JIS X 0213:2004の文字、そして印刷標準字体に対応した字形を含みます。このほか、アドビシステムズ独自の調査に基づく主要な異体字を含み、Adobe-Japan1-6は23,085字を収容しています。
- 「主に字形集合」?
- 「JISC 6226-1978」は、正しくは「JIS C 6226-1978」だが、p.59に「本書では、煩わしさを避けるために、以後、JIS X 0208の名称を用います」とあるので、適切な表記は「JIS X 0208:1978」。
- IVDコレクションとしてのAdobe-Japan1(漢字のみを含む)とフォントのレパートリを規定しているAdobe-Japan1-X(非漢字も含む)の説明がごっちゃになっている気がする。
p.152

p.153

- 21行目。IVSを含む文字列は「U+845B U+E0100 U+98FE」ではなく「U+845B U+E0100(0xDB40 0xDD00) U+98FE U+533A」。
- 25行目。「ccLenInTextElement = 2」ではなく「ccLenInTextElement = 3」。
- 29行目。「U+257A9(0xD855 0xDFA9)」は「IVSを含む文字列」ではない。
- 37行目。「0xE0100」→「U+E0100」。
p.154
検索、置換の対象となる文字列を以下とします。A、B、C、D、Eは、それぞれ基底文字、そしてIVSは異体字セレクターを意味しています。

- IVS(などの結合文字列)を構成している場合以外には、文字を「基底文字」とは呼ばないと思う。
- 異体字セレクタを「IVS」と略記しているのはなぜ? 「VS」という一般的な(UTS #37でも使われている)表記があるものを、わざわざ非常にまぎらわしい呼び方をするのは(そして、それを書籍に掲載することで広めるのは)やめてもらいたい。
- 図における「IVS」が異体字セレクタ一般を表現しているのか特定の異体字セレクタを表現しているのかわからない(特定の異体字セレクタだと考えないと以下のロジックが成立しないのだが、それが最初の段階ではわかりにくい)。
異体字セレクターを含まない「B」による検索は、正確な字形による検索ではなく、字体の合致する文字、もしくは文字列を検索していると想定します。
- 「字体の合致する文字」ではなく、「Bと符号位置の一致する文字」。文字(character)において字体は包摂されるので、符号位置が同じであっても字体が同じであるとは限らない。
- 以後繰り返さないが一度だけ言っておくと、「字形による検索」ではなく「グリフによる検索」と書いてほしいところ(「字形」は抽象的な形ではない)。
p.155
この例は、異体字セレクターによる字形の指定がないことから、字形の合致する文字、もしくは文字列ではなく、字体の合致する文字、もしくは文字列の検索であると想定します。
- 「字体の合致する文字」ではない。
- 「字体の合致する文字」ではない。
*1:さまざまな人からの情報をベースにしています。個々にお名前を挙げることはしませんが、皆さんありがとうございます!