『Unicode IVS/IVD入門』へのツッコミ・第4章編
- 『Unicode IVS/IVD入門』(田丸健三郎、小林龍生)を読んでいたら、いくつか気になる点があったので、まとめてみることにした。とりあえず、第4章(37ページ分)だけ。時間と気力があれば、今後、他も追加していくかも*1。組版上の突っ込みは(ひどい例以外は)省いた*2。
p.103
ISO/IEC 8859は《中略》パート16まで定義されています(パート15は破棄)。
- 破棄されたのはパート12。
p.104
「ISO-10646」の文字集合
- 「ISO-10646」→「ISO/IEC 10646」。
たとえば、1面19区75点を符号位置とする文字をシフトJISで8ビット符号化した場合0x8A6Bとなる文字を例に見てみましょう。この文字は、葛飾区の「葛」という文字ですが
- 「葛」はシフトJISで「0x8A6B」ではなく「0x8A8B」。
p.106

- 「U+000000」→「U+0000」(Unicodeスカラ値を0で埋めて表記するのは4桁まで。他についても同じ)。
- 「U+00FFFF」→「U+FFFD」(0面の末尾はFFFDでもFFFFでもいいと思うが、同じ表の中でDだったりFだったりするのはおかしい)。
- 「U+010FFD」→「U+1FFFD」(数値の間違い)。
p.107

- 「A」→「a」。
- 「B」→「b」。
- 「C」→「c」。

- 「A」→「I」。
- 「A」→「U」。

- Unicode 1.1は1993年。
- 「技術仕様としては、JIS X 0213:2004に対応」は、このバージョンでサロゲートペアが規格化された(から、将来のJIS X 0213を収録できる空間がある?)というようなことを言いたいのかもしれないが、ちょっと意味不明。
- 「サロゲートペア303文字を追加」とあるが、「303文字」はJIS X 0213ソースでCJK統合漢字拡張Bに入った漢字のみの数(2001年の時点では302文字)。
p.108

- 2002年の段階で「JIS X 0213:2004に正式対応」というのはおかしい。「JIS X 0213:2004の文字を(すでに)すべて含んでいる」というようなことを言いたいのだとは思うが。
- 「サロゲート領域にフェニキア文字など追加」とあるが、BMP外を「サロゲート領域」とは言わないと思う。この本でも別のページでは「U+D800〜U+DFFF」を「サロゲートエリア」と呼んでいる。
p.109

- 「U+3068」→「U+30C8」。U+3068は「と」。
- 「3068 3099」→「U+30C8 U+3099」。U+3068は「と」。「U+」が抜けている。
- 「3069」→「U+30C9」。「U+」が抜けている。
- 右から2番目の「ド」は「合成文字」ではなく「合成列」または「結合文字列」では?
p.110

- 「0x309A」→「0x3099」(5箇所)。
用語
「は」(0x306F)+「゜」(0x309A)の組み合わせにおける「は」を基底文字、「゜」(0x309A)を結合文字、そしてこれに二つのシーケンスにより構成される「ぱ」を合成文字といいます。
- 「合成文字」ではなく「合成列」または「結合文字列」では?

- 「結合順序」の意味が不明。
- ダイアクリティカルマークの位置がぐちゃぐちゃ。特にセディラの位置は点線で描いたマルの下でないとおかしい。
- 右と左でハングルのフォントが変わっている意味が不明。
- オリジナルのUAX #15の図は、以下のとおり。

文字コード、もしくはそのシーケンスが異なっていたとしても、意味が同じ、字形も同じ文字を正規等価であるという一方、意味は同じでも、見た目が異なる互換等価というものがあります。
- 互換等価の定義は「互換分解によって同じ文字(列)になるもの」であり、正規等価は互換等価のサブセットとなる。したがって互換等価は「見た目が異なる」わけではない。
p.111

- ARABIC LETTER NOONの語頭形、語中形(または語尾形)、一般形(下図を参照)を示したかったのだと思うが、語頭形がダブっている。

p.112

- 「03B」→「003B」。
- NFD欄の「Ω」とNFC欄の「Ω」は(どちらもU+03A9なのだから)同じはずだが違っている。NFD欄の「Ω」はリュウミンで、NFC欄の「Ω」はMS明朝で表示しているようなのだが、なぜそんなことに。
- 「U+0212A」→「U+212A」。
- 正規化前のケルビン記号と正規化後の「K」でフォントが違っている(MS明朝と中ゴシックBBB)理由が不明。

p.113

- ダイアクリティカルマークの上のほうが切れている。

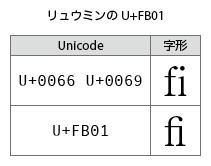
- 「合字“fi”は」の部分が、fi合字のU+FB01「fi」についての記述でありながら、合字になっていない(fとiの文字列となっている)。ゴシック系の書体だと、(表4-5で用いられている中ゴシックBBBのように)U+FB01を「fとiがくっつかない形」で実装しているものもあるが、本文書体はリュウミンなので、fとiが一体化していないとおかしい(下図を参照)。
- 「“5”からは」の部分は、組版的な処理によって上付きとなった「5」ではなく、U+2075「⁵」についての記述なのだから、「⁵」でないとおかしい。

- 「互換合成文字」という用語が説明なしで登場。
- この表における互換合成文字は「fi」「⁵」「℡」だが、それが明示されていない。
- U+FB01「fi」の表示に(fとiがくっつかない形の)中ゴシックBBBを用いているのは、間違いではないにしろ、少なくとも親切ではないと思う。
- NFKD欄とNFKC欄の「2 5」にはスペースを入れているが、NFD欄とNFC欄の「2⁵」にはスペースが入っていない。「NFD/NFCでは見た目が変わらない」という点を強調したかったのかもしれないが、このあたりは統一されていないとおかしい(参考までに、以下にUAX #15の図を載せておく)。

正規化形式C(NFC)は、正準合成文字をなるべく使用し、互換等価である文字間の差異を維持します。
- 「正準合成文字」という用語が説明なしで登場。
p.114
表4-6 往復変換ができない漢字は、コードページ932、そしてJIS X 0213に規定されている文字のうち、正規化により元の情報が失われる文字の一覧です。

- 表4-6からコードページ932のみに含まれる漢字(JIS X 0213に含まれない漢字)が抜けている。抜けている文字は、下図のとおり。
- 細かいことを言えば、表のヘッダの「区点番号」「符号位置」という表記もどうかと思う(区点番号のことを符号位置とも言うので)。というか、JIS X 0213の話なので、「区点番号」ではなく「面区点番号」。
- 表のヘッダの「NFD」という表記も、よくわからない(もちろんNFDでも化けるのだが、NFC/NFD/NFCK/NFCDのどれでも化ける)。

また、これら互換漢字については、Unicode IVDに追加登録し、異体字セレクターを用いて使用可能にするという議論もあります。
- それはUnicode IVDではなくStandardized Variantsでは?
p.117
特に、内閣告示として法的な意味合いを持つものとしては、1949年に国語審議会の答申を経て告示された当用漢字が最初になるのではないでしょうか。
- 当用漢字は1946年。1949年は、当用漢字字体表。
p.118
当用漢字

- 当用漢字は1949年ではなく1946年。
- 改定常用漢字表の内閣告示は11月30日。6月7日は答申。
国の施策として当用漢字、常用漢字などが定められていく一方で、JIS X 0201、JIS X 0208(旧JIS C 6226)が工業規格として定められます。
- 「JIS X 0208(旧JIS C 6226)」と書くのなら、JIS X 0201は「JIS X 0201(旧JIS C 6220)」では?
p.119
図4-8 JIS漢字の水準が示す通り、第1水準漢字は2,960字、第2水準漢字は3,388字の形6,353字。これに第3水準漢字の1,259字と第4水準漢字の2,436字、そして非漢字659字を加えると、10,038字になります。
- その通りに計算しても10,038字にはならない。
- この計算では、JIS X 0208の非漢字524字を入れるのを忘れている。
- 第2水準漢字は6,353字ではなく6,355字(6,353字はJIS83の数字)。
p.122
これら三つ(引用者注:シフトJIS、Shift_JIS、コードページ932)の共通点、そして最も重要な点は、いずれもASCIIと共存が可能であることが挙げられます。
- JIS X 0208:1997が規定しているShift_JISはもちろん、シフトJISだろうとコードページ932だろうと、ASCIIとの共存は不可能。
表4-8 JIS X 0201の文字コード表を見てください。ASCIIとの違いは0xA0〜0xFFが使用され、日本語固有の文字が割り当てられていること、そして0x5Cの符号位置の文字が「/」ではなく「¥」になっていることです。
- ラテン文字・片仮名用8ビット符号(図4-8)だけがJIS X 0201であるかのように書かれているが、そんなことはない。JIS X 0201は、ラテン文字用7ビット符号、片仮名用7ビット符号、ラテン文字・片仮名用7ビット符号、ラテン文字・片仮名用8ビット符号を規定している。
- ASCIIの0x5Cの文字は、スラッシュではなくバックスラッシュ。
同じ符号位置にASCIIとJIS X 0201では、異なるグリフを割り当てています。
- ここは「グリフ」ではなく「文字」では?
これにより、文字データを交換する際にそのデータが参照している規格がJIS X 0201なのか、それともASCIIなのかを明示せず、そのどちらの可能性もある場合は、0x5Cで示される文字が「/」なのか、「¥」なのかを特定できないことを意味します。
- スラッシュではなくバックスラッシュ。
p.123

- 0x7Eがチルダになっているが、正しくはオーバーライン。
- 0xA0が「SP」、0xFFが「DEL」となっているが、正しくはどちらも未定義。
まず、JIS X 0201についてですが、これはASCIIとISO 2022を組み合わせたようなものとなっています。
- JIS X 0201の初版(JIS C 6220-1969)が出たときには、まだISO 2022は存在していない。
具体的には、US-ASCII、ISO/IEC 646と呼ばれる文字集合とほぼ同じコントロールコードと文字をC0、G0集合に、半角カタカナをG1に収容しています。結果として、C1が未割当となっています。
- シフトJISの半角カタカナを「半角カタカナと呼ぶな」などと言うつもりはないが、JIS X 0201を語る文脈で半角と書いてはダメだと思う。
- C0、G0、G1、C1(集合)とあるのは、CL、GL、GR、CR(領域)では?
コンピュータが普及し、文字が扱われ始めた頃、ドイツ語、ロシア語などのラテン語を祖とする言語の多くが8ビットの文字コードであるASCIIを拡張して符号化されてきました。
- ASCIIは7ビット。
一方で日本語をはじめとするアジアの言語は8ビットで符号化することができず、ダブルバイト文字と呼ばれるような方法によって文字を符号化してきました。
- それはアジアの言語というより漢字文化圏の話では?
ISO/IEC 2022は、これらさまざまな言語で使用される複数のキャラクタセットを同一の仕組みで7ビット符号化するための方法として考え出されました。
- JIS X 0208(JIS C 6226-1978)のほうが先にあったように読めるが、ISO 2022の初版は1973年
- ISO 2022には8ビット符号もある(というか、以下の記述も8ビットを前提としたものになっている)。
表示、コントロールに使用するエリアをそれぞれC0、C1、GL、GR、その符号化された文字を管理するエリアをG0、G1、G2、G3と呼びます。
- 使用するエリアはC0ではなくCL、C1ではなくCRでは?
ISO/IEC 2022で使用するコントロールコード、エスケープシーケンスは、GLにG0からG3を、GRにG1からG3を呼び出すために使用します。
- 呼び出し以外(G0、G1、G2、G3への指示など)にも使う。
p.124

- 96文字集合はG0に指示できない。G0については「96文字」→「94文字または94n文字」。
- G1、G2、G3については「96文字」→「94文字、94n文字、96文字、96n文字」。
- 「0x81」(上、やや右)は「0x80」の誤り。
- 「C0」ではなく「CL」、「C1」ではなく「CR」では?
JIS X 0201に話を戻すと、JIS X 0201の未割当であるC1で使用できる文字数は32字
- 「C1」ではなく「CR」では?
そこで、シフトJISは2バイト目に未割当領域の使用を諦め、G0およびG1を使用する選択を行っています。
- 「未割当領域の使用を諦め」→「未割当領域だけを使うのは諦め」。
- 「G0およびG1」→「GL、CR、GR」。
p.125

- 「ウ」は「83 42」ではなく「83 45」。
p.127

- 「ASCII」→「JIS X 0201ラテン文字」。
(コードページ932の説明として)
「NEC特殊文字」、「NEC選定IBM拡張文字」、「IBM拡張文字」の統合を含むJIS X 0201:1997、JIS X 0208:1997の符号化文字集合の「Shift_JIS」符号化方式によるもの。
(コードページ51932の説明として)
IANAにはUS-ASCII、JIS X 0208:1990、JIS X 0208:1990、JIS X 0212:1990、そしてJIS X 0201:1997の半角カタカナ含む符号化文字集合「euc-jp」として登録されている、Windows上では、JIS X 0201:1997、JIS X 0208:1997の符号化方式の一つとして定義されている。
- ???
p.129
そして、iso-2022-jpは、ASCII、JIS X 0201:1976、JIS X 0208:1978、そしてJIS X 0208-1983の四つの文字コードをサポートしています。
- 間違いではないが表記が統一されていない。「JIS X 0208-1983」→「JIS X 0208:1983」。
- 「そのような」→「そのように」。

- 「l」は「9C」ではなく「6C」。

- 間違いではないが表記が統一されていない。「JIS C 6226-1978」→「JIS X 0208:1978」*3。
p.130

- SOとSIを「ESCシーケンス」とは呼ばないと思う。
- それぞれ単独で用いるSOとSIを「0x0E 0x0F」と文字列(シーケンス)のような形で掲載しているのもおかしい。
p.131
UTF-8の符号化形式としては、最大0x7FFFFFFF(6バイト)までの値を取り得るが、元となるUnicodeのスカラー値の範囲がU+000000〜U+10FFFFであることから、それに伴い符号長の最大値も4バイトとなる。
- 「0x7FFFFFFF」→「FD BF BF BF BF BF」。
- 「U+000000」→「U+0000」。

- 「0x2000B」→「0x0002000B」。
p.132
また、8ビットを最小単位した符号方式であることから
- 「最小単位した符号方式」→「最小単位とした符号化方式」?


p.136
Unicodeは制定当初、世界で使用されているすべての文字を16ビットの符号空間に収容するという理想の下、2の16乗=65,536文字を収容可能にした文字コード規格でした。最初のバージョンでは2万文字の空き領域を残し、約4万文字を収容しています。そのため、初期のバージョンでは、UTF-16で符号化されたデータにおいて、1文字が16ビットを超えることはありませんでした。その後、初期のバージョンに含まれていなかった文字の追加要求が2万文字を大幅に超え、16ビットの符号空間に全ての文字を収容するという当初の構想は破綻してしまい、Unicodeは符号空間の拡張を行いU+000000からU+10FFFFを使用することになります。この符号空間の拡張で考えなくてはならなかったのが、UTF-16の符号化方式です。UTF-8は、その仕組みから拡張された符号空間への対応は論理的にも容易でしたが、UTF-16は新たな手法を考え出さなくてはなりませんでした。
そこで考え出されたのが、シフトJISに似た仕組みのサロゲートエリア、サロゲートペアなのです。
p.137

- 「U+1000」→「U+10000」。
- 「1,114,111」→「1,114,112」。
- 「U+D800〜U+DFFF」→「D800〜DFFF」(Unicodeスカラ値ではないので「U+」は付けない)。

- 追加面のUnicodeスカラ値をUTF-16に変換するロジックが間違っている。Unicodeスカラ値から0x10000を引いて1面分シフトしてからでないと「yyyy yyyyyyxx xxxxxxxx」→「110110yy yyyyyyyy 110111xx xxxxxxxx」のような変換はできない。
U+10000よりも大きい符号位置では、Unicodeスカラー値を10ビット+10ビットに分割し、それぞれの値に0xD800、0xDC00をORすることでサロゲートペアのコードを求めることができます。

- 直前の表4-17と同じ間違い。変換前が20ビットだという時点でおかしい。
p.138

- 「U+20000B」→「U+2000B」。
p.139
- UCS-2について解説しているが、「UCS-2がISO/IEC 10646:2011ではdeprecated(非推奨/廃止予定)とされた」という点に触れていない。ISO/IEC 10646:2012には「NOTE — Former editions of this International Standard included references to a two-octet BMP form called UCS-2 which would be a subset of the UTF-16 encoding form restricted to the BMP UCS scalar values. The UCS-2 form is deprecated」とある。
UCS-4はISO/IEC 10646の標準的な符号化方式として使用されています。UCS-4では、全ての文字コード空間を231のエリアで管理しています。また、これを256×256からなる面の計256面、そして256面を一つの集まりを群とした計128群にて管理しています。しかし、現在の文字の割り当ては最初の群のBMP、および16面までの範囲で行うとしています。これにより、他の符号化方式とUnicode標準(0から0x10FFFF)との互換性を維持しています。一部の違いを除いて、UCS-4とUTF-32は同じと見ることができます。
- 「全ての文字コード空間を231のエリアで管理」→「全ての文字コード空間を231のエリアで管理」。
- 「256面を一つの集まりを群とした」は「256面を一つにまとめて群とした」みたいなこと?
- 情報が古い。ISO/IEC 10646 Amendment 2:2006では、0群17面以降は将来的にも使用しないことになっている。JIS X 0221:2007には「群00の面11〜FF及びその他の群のすべての面(すなわち、群01〜7Fの面00〜FF)は、将来にわたって使用しない」とある。また、現行のISO/IEC 10646には、もう「群」についての記述はない。
*1:第4章以外については、「IVS本に容赦なく突っ込みまくるNAOIさん」を参照してください。今回のエントリは、Twitterなどにおける皆さまの貴重なツッコミから得られた情報を含んでいます。ツッコミerの皆さま、Togetterでていねいにまとめてくれた皆さま、ありがとうございます!
*2:スペースを入れるべきかどうかといったレベルのツッコミは基本的には省いたが、スキャンして掲載した図には鉛筆で印が付けてあったりするかもしれない。「スペースかハイフンか」の違いには突っ込んだ。
*3:制定時の規格番号「JIS C 6226-1978」は間違いではないのだが、pp.58-59で「本書では、煩わしさを避けるために、以後、JIS X 0208の名称を用います」と宣言しているので。