IVS本へのツッコミ・第3章編
- 最後まで続ける気力があるかどうかわからないままはじめた『Unicode IVS/IVD入門』(田丸健三郎、小林龍生)への突っ込みシリーズだが、今回、第3章についてまとめたことで、ゴールが見えたかなというかんじ*1。
p.58
3.2.2 文字について
- 「3.2.2」→「3.1.2」。
p.59
表3-1に、変更された符号位置を列挙します。
- 変更された符号位置を列挙しているのは「表3-1」だけではなく、「表3-1、表3-2、表3-3」。

- 「靱」のUCS符号位置は「U+8ACC」ではなく「U+9771」。
- 「靭」のUCS符号位置は「U+8ACC」ではなく「U+976D」。
P.60

- 「表3-1 入れ替えられた22組」に「槙/槇」が入っているが、これは「表3-2 JIS X 0208:1983で追加された符号位置との入れ替え4組」のほう。
- 逆に表3-1に入るべき「桧/檜」が、表3-2に入っている。
- 表3-2の備考欄の「人名漢字」は「人名用漢字」。
- 表3-2の「遥」のUCS符号位置は「U+8ACC」ではなく「U+9065」。
P.61

- 「麹」の備考欄に「麺」についてのコメントが入っている。
- 「麺」の備考欄に「頬」についてのコメントが入っている。
- 「頬」が「手書き差」なら、「侠」(前頁)や「填」や「莱」も手書き差では? 改定常用漢字表が挙げている例だけを掲載しているのだとしても、「填」は該当する。
p.62
日本の国語施策は、1900年(明治33年)の国語調査会の設置に始まります。この活動は、さまざまな経緯を経て、1934年(昭和9年)の国語審議会の設置へとつながっていきます。
- 「1900年(明治33年)の国語調査会」というのがわからないのだが、「1902年(明治35年)の国語調査委員会」のこと? それとも、国語審議会の前身ということなら「1921年(大正10年)の臨時国語調査会」?
もう一つ、この時期の国語施策として忘れてはならないのは、「人名漢字別表」です。
- 「人名漢字別表」→「人名用漢字別表」。
p.63
3.3.3 83JISの勇み足?
- 「3.3.3」→「3.2.3」。
p.64
JIS X 0213:2004制定時に、168字が表外漢字字体表の印刷標準字体にあわせて変更され、10文字が追加されました。
- 168字のうち「芦」は印刷標準字体ではなく簡易慣用字体にあわせた変更。
p.66

- 区分欄で「第4水準」となっている箇所は、すべて正しくは「第3水準」。
表3-4 JIS2013:2000で追加された康煕字典体別掲字
- 「JIS2013:2000」→「JIS X 0213:2000」。
p.71

- 1-47-66は「屮」ではなく「屮」。その隣の欄は「*」ではなく「屮」。
- 1-86-87(U+FA46)「渚」、1-87-58(U+FA15)「凞」、1-87-79(U+FA16)「猪」、1-88-05(U+FA4A)「琢」が抜けている(下図参照)。
- 「﨔」など「対応する統合漢字」欄に「*」が入っている文字は、「名前にはCOMPATIBILITY IDEOGRAPHと付いているが互換漢字ではなくCJK統合漢字」とされている文字。「CJK Compatibility Ideographsと対応付けられている漢字」というタイトルの表の「互換漢字」欄に、これらCJK統合漢字が入っているのはおかしい。

p.73

- 統合漢字欄に「*」が入っている文字については前項で述べたとおり。
- 最後の註も「CJK互換漢字ブロックに入っているCJK統合漢字」をCJK互換漢字扱いしているのでおかしい。
- 「﨏」と「﨑」はいずれも「CJK互換漢字ブロックに入っているCJK統合漢字」なので、この表に入っていること自体がおかしいのだが、面区点位置順のリスト中で最後に置かれているのも変。
p.74
表外漢字字体表では、「いわゆる康煕字典体」とは「明治以来、活字字体として最も普通に用いられてきた印刷文字字体であって、かつ、現在においても常用漢字の字体に準じた略字体以上に高い頻度で用いられている印刷文字字体」および「明治以来、活字字体として、康熙字典における正字体と同程度か、それ以上に用いられてきた俗字体や略字体などで、現在も康熙字典の正字体以上に使用頻度が高いと判断される印刷文字字体」のことと位置付けています。表外漢字字体表には、この原則の適用例として1022組都合1044の漢字字体が掲げられていますが、ここに掲げられた1044字体はあくまでも例示であり、例示されていないその他の漢字についても、原則が適用されることを忘れてはなりません。
- 「いわゆる康熙字典体」の説明として表外漢字字体表から引用されている部分は、「いわゆる康熙字典体」ではなく「印刷標準字体」の説明。
- 「1022組都合1044の漢字字体」の意味が不明。数からすると、「印刷標準字体1022と簡易慣用字体22で合計1044の漢字字体」ということかと思うが、そう考えても、やはり意味が通らない。「明治以来、活字字体として、康熙字典における正字体と同程度か、それ以上に用いられてきた俗字体や略字体などで、現在も康熙字典の正字体以上に使用頻度が高いと判断される印刷文字字体」というのは、「俗字体・略字体を印刷標準字体と認定する条件」であって、「俗字体・略字体を簡易慣用字体と認定する条件」ではない。
p.75
3.6.3 表外漢字字体表と完全に一致する文字と紛らわしいUCSの文字
JIS X 0213:2000およびUCSに同一の字形があった815字の印刷標準字体と、5字の簡易慣用字体について、JIS X 0213:2004では何ら変更は行われていません。
- タイトル中の「表外漢字字体表と完全に一致する文字と」は不要ではないかと思う。
- 他の箇所では「字形」という用語が「抽象化された形状」の意味で使われているので、そのつもりで読むと、まったく意味がわからない。
- 「JIS X 0213:2000およびUCSに同一の字形があった815字の印刷標準字体」とあるが、815字の印刷標準字体は、JIS X 0213:2000、JIS X 0208およびUCSに同一の字形があったもの。この「JIS X 0208」は省略できない(たとえば補助漢字ソースでUCSに入っている「鷗」なども表外漢字字体表と同じ字形である可能性があるため、「815字」ではなくなる)。
- 「5字の簡易慣用字体について、JIS X 0213:2004では何ら変更は行われていません」とあるが、簡易慣用字体のうちJIS X 0213:2004で変更が行われていないのは5字ではなく21字。「JIS X 0213:2000、JIS X 0208およびUCSに同一の字形があった簡易慣用字体」でも20字。この簡易慣用字体についての記述は、JIS X 0213:2004の「解説」の「3.1.2 b」もおかしい。

- 「一部規格票には誤植あり」というのは、おそらく「冑」のUCS符号位置が「00005159」となっている(正しくは「00005191」)点を言っているのだと思うが、わざわざそのように指摘しながら、なぜ間違いをそのまま掲載しているのか……。「U+5159」は、正しくは「U+5191」。
3.6.4 印刷用標準字体との間の微細なデザイン差を変更した漢字
- 「印刷用標準字体」→「印刷標準字体」。

- 「面句点位置」→「面区点位置」(表3-8についてはp.77までに3回出現)。
p.77

- 「面句点位置」→「面区点位置」。

- 「面句点位置」→「面区点位置」。
- 「蘆」ではなく「芦」。正しくは、下図のようになる。

p.78
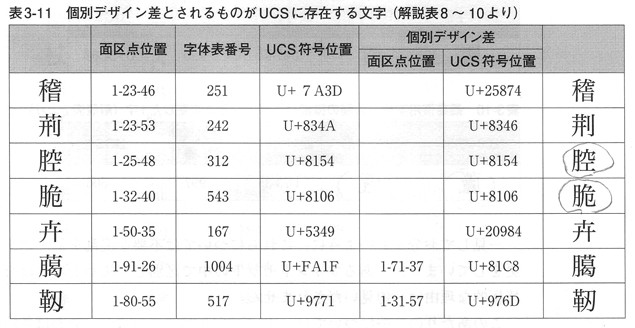
- 「腔」と「脆」の個別デザイン差(下図を参照)が、JIS04グリフと同じになっている。
- それ以前の問題として、「腔」と「脆」の個別デザイン差はUCSの別の符号位置には存在しないので、この表に入っていること自体がおかしい。
- 「腔」と「脆」の個別デザイン差がUCSに存在するとする誤りは、JIS X 0213:2004の「解説」にも見られる(pp.51-52)。IVS本に突っ込むつもりで、規格票のミスを発見してしまった。

p.79

- 「面句点位置」→「面区点位置」(表3-12についてはp.80までに4回出現)。
p.81

- 「面句点位置」→「面区点位置」(表3-13についてはp.82までに2回出現)。

p.84
表外漢字字体表の字形を尊重する場合は、この新たに追加された符号位置を用いることが望ましいでしょう。
- 「痩」は簡易慣用字体のほう(新たに追加された符号位置でないほう)が2010年に常用漢字に入っているので、表外漢字字体表の趣旨を尊重するなら、こちらを使うべき。
- 「2000年」→「2010年」。
p.85

- IBM拡張文字のリストのうち2つの中黒(・)が余計。
- IBM拡張文字のリストから「墲」と「薰」が抜けている。
- おそらく文字を出力するのに用いた94文字単位のループ処理で、スキップすべきコード(下図で矢印が指している0xFA7Fなど)を中黒として拾ってしまっているぶん、94文字のブロック(下図、黄色地)の末尾の文字を取りこぼしたのだと思う。

p.86

- NEC選定IBM拡張文字のリストのうち2つの中黒(・)が余計。
- NEC選定IBM拡張文字のリストから「德」と「釚」が抜けている。
- NEC特殊文字に中黒(・)が1つ入っているのは、上記の例とは異なり、単に0x875Eの未定義文字を中黒として表示しているだけだと思うが、他の未定義文字は表示されていない(そのようなルールだと思われる)ので、これも余計。
この表をご覧になって気づいた方もいるかと思いますが、それぞれに相当数の重複した漢字・記号が存在しています。重複の種類には二種類あり、一つはJIS X 0208に含まれている漢字・記号との重複、もう一つはJIS X 0208に含まれず、独自に拡張された文字・記号が重複しているケースです。たとえば表3-15の文字は、コードページ932として固有でありながら、JIS X 0208含まれていない記号です。374文字あります。
- NEC選定IBM拡張文字、IBM拡張文字には、「JIS X 0208に含まれている漢字」との重複は、基本的にないと思う。
- 「表3-15」がゴシック体(このエントリの引用中ではボールドで表現)になっていないのはママ。
- 「JIS X 0208含まれていない」→「JIS X 0208に含まれていない」。
- 「記号です」→「漢字・記号です」。
- 「374文字あります」と書かれているが、表3-15でリストアップされているのは(重複もカウントすると)398文字。ただし、後述するように、表3-15は間違っている。では、本文中の「374文字あります」の方が正しいかというと、こっちも間違っている。数え方はいろいろ考えられるので「正しい文字数」を挙げることはしないが、どう数えてもそんなに少ないわけがない。
pp.87-102

- 表のタイトル。「コードページ932でありながら」という表現もしっくりこないが、それは措くとして「JIS X 0208含まれていない記号」→「JIS X 0208に含まれていない漢字・記号」。
- タイトルに突っ込んだあとで言うのも何だが、この表は「CP932に含まれていてJIS X 0208に含まれていない漢字・記号」をリストアップしたものではない。
- 表の最初に掲載されている9つの記号「≒≡∫√⊥∠∵∩∪」は、いずれもJIS X 0208の2区に含まれるもの。
- 表のヘッダの3つめのセルに「CP932(JIS X 0208)」とあるのは、この欄にJIS X 0208の(シフトJISにおける)コードが入る場合があることを示唆しているのだと思うが、タイトルとの矛盾に気づかなかったのだろうか。
- JIS X 0208に含まれる「≒≡∫√⊥∠∵∩∪」とは逆に、JIS X 0208に含まれない(つまり、この表に載せるべき)丸付き数字などがリストアップされていない。
- この全16ページにおよぶ表3-15にリストアップされているのは結局のところ何かというと、「CP932に重複して含まれる文字」だと思われる。根本的に間違っているわけで、どうしようもない。
- 表のヘッダの5番目のセルに(突然英語で)「Attribute」とあるのは、「属性」などと訳してしまうと違和感があるので英語にしたのだろうが、日本語に訳しておかしいものは、英語でもおかしい。
p.102
付録の文字コード表をご覧になればお分かりのように、すべてJIS X 0213:2004には含まれています。
- 文脈上「CP932の記号および漢字はすべてJIS X 0213:2004に含まれる」と主張しているとしか解釈しようがないが、もちろん、そんなわけがない。CP932に含まれていてJIS X 0213:2004に含まれていない記号・漢字の例を適当に挙げておけば、「¦」とか「髙」とか「仼」とか。
*1:さまざまな人からの情報をベースにしています。個々にお名前を挙げることはしませんが、皆さんありがとうございます!